
New Era: Beyond Chatbots
It wasn't long ago that we were impressed if an AI could write a limerick or summarize an email. Fast forward to late 2025, and that era feels like ancient history. Today, if you're a developer, a business leader, or just a power user, you aren't looking for a chat partner—you're looking for a reasoning engine.
Release of Gemini 3 Pro, Grok 4.1, and GPT-5.1 has fundamentally fragmented the market. We no longer have a single "best" model. Instead, we have specialized tools that excel in radically different environments. Hardware integration is deepening too; for instance, even upcoming mobile hardware like the OnePlus 15R is rumored to include dedicated NPU slices optimized specifically for these quantized models, bringing this power to your pocket.

But running them in the cloud is where the real power lies. The debate has shifted from "who writes better poetry" to "who can process a 500-page legal discovery document cheaper?" and "who can build a web app from scratch without crashing?"
Gemini 3 Pro: Enterprise Architect
Google DeepMind has stopped playing catch-up. With Gemini 3 Pro, they have arguably built the most robust infrastructure for AI. It's not just a model; it's an ecosystem play. If you are using Google Gemini today, you are seeing the tip of the iceberg.
"Humanity's Last Exam" Benchmark
Let's talk numbers. The HLE (Humanity's Last Exam) benchmark was designed to be impossible for rote-memorization machines. It requires multi-step logic, verifying sources, and discarding red herrings. Gemini 3 Pro scored 45.8%. To put that in perspective, GPT-4o scored in the low 20s. This represents a generational leap in "System 2" thinking—the ability to stop, think, and plan a response before generating tokens.
Antigravity IDE & Vibe Coding
For developers, the killer feature isn't the chat—it's the integration. Google's "Antigravity IDE" allows for what the community calls "vibe coding." You describe the *intent* of the software, and Gemini 3 manages the file structure, dependency trees, and deployment scripts. It doesn't just write snippets; it manages the repo.
Cost Reality Check
Sticker price is high: $2.00 per million input tokens. However, Google's Context Caching changes the math. If you are a law firm querying the same case files daily, you pay to upload them once. Subsequent queries cost ~90% less ($0.20). This makes Gemini the default choice for "static knowledge" businesses.
Grok 4.1: Research King
While Google focuses on depth, xAI is focusing on width. Grok 4.1 (and its speed-optimized cousin, Grok 4 Fast) has democratized "long-context" computing. You can access it via the API or Grok web.
2 Million Tokens: Why It Matters
Most users don't realize how small 128k tokens (the 2024 standard) really is. It's a couple of books. Grok's 2 Million Token window allows you to upload an entire codebase, a year's worth of financial logs, or the complete transcript of a 50-hour video series.
In our testing, we fed Grok 4.1 the entire documentation for the Linux Kernel v6.1. We then asked it to find a specific driver dependency conflict. It found it in 14 seconds. That is needle-in-a-haystack retrieval at a scale no other model currently matches for the price.
$0.20 Price Disruption
xAI is playing a brutal price war. Grok 4 Fast is priced at ~$0.20 per million input tokens *without* caching. For a startup analyzing user logs, this means your monthly bill could be $500 on Grok vs $5,000 on Gemini or GPT-5. If you are processing high-volume text where "good enough" reasoning is acceptable, Grok is the only economically viable option.
GPT-5.1: Agentic Coder
OpenAI has pivoted. GPT-5.1 is less of a chatbot and more of an "agent." Available via ChatGPT, its primary strength lies in autonomy.
For those deeply entrenched in the Microsoft ecosystem, the battle often shifts to how this integrates with Windows. It's worth reading our breakdown of Copilot vs ChatGPT to see how the wrapper changes the experience.

SWE-Bench and Reliability
On the SWE-Bench Verified (Software Engineering) benchmark, GPT-5.1 holds a score of ~76%. But the score masks the reality: GPT-5.1 is much better at *correcting itself*. When it writes broken code, it can read the error log, understand the stack trace, and fix it without human intervention. This "agentic loop" is what makes it the preferred pair programmer for senior engineers.
Meanwhile, the Microsoft Copilot 2025 update has bridged the gap for enterprise users, bringing these GPT-5 capabilities directly into Word and Excel, further cementing OpenAI's utility in the office.
Performance Comparison
Benchmarks don't tell the whole story, but they provide a standardized way to measure capabilities. Here's how the three models stack up against each other in key areas:
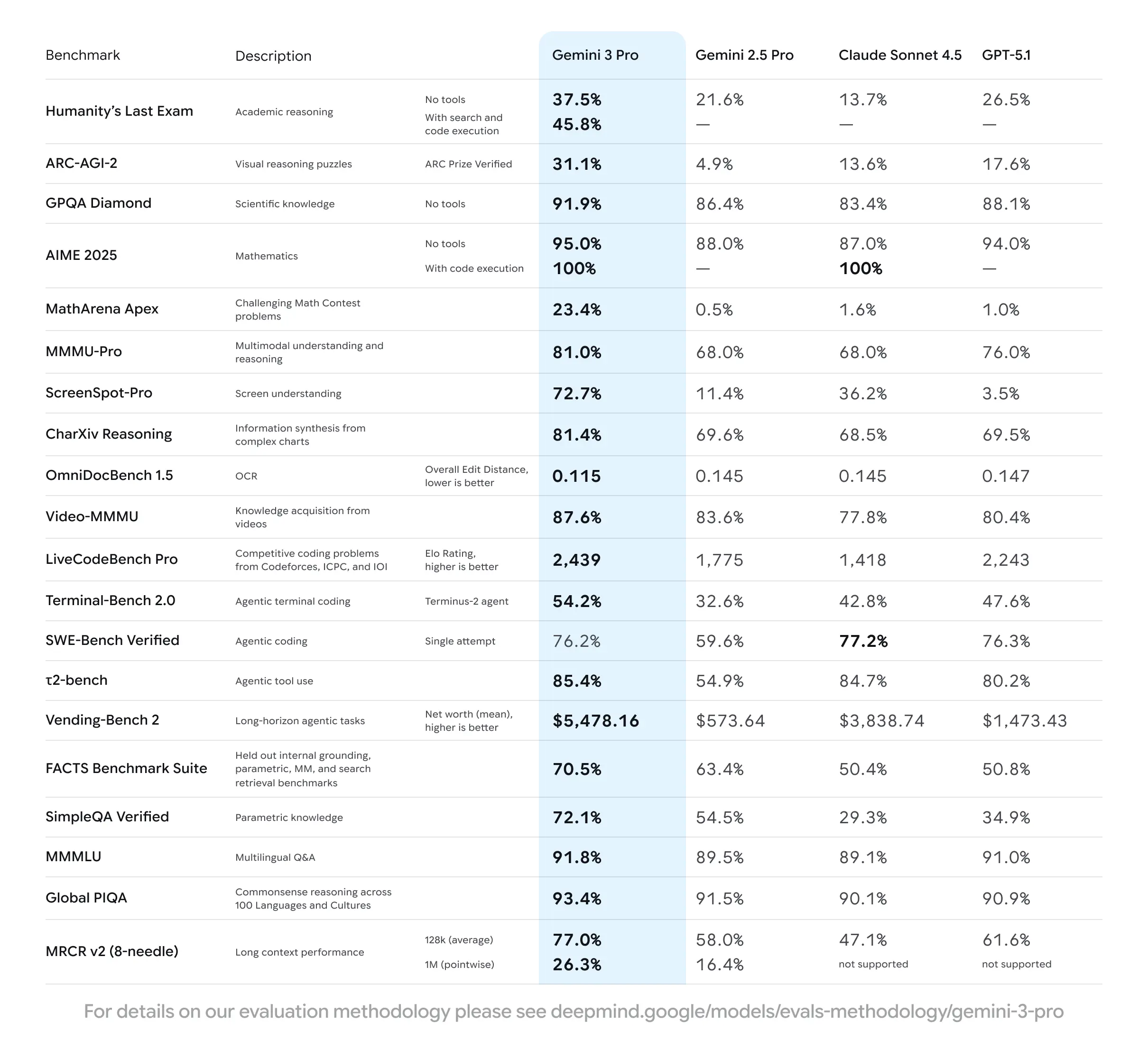
Key Benchmark Scores
AGI Progress Analysis
Artificial General Intelligence (AGI) remains the ultimate goal, and each of these models represents a step in that direction. Let's analyze their progress across key AGI metrics:
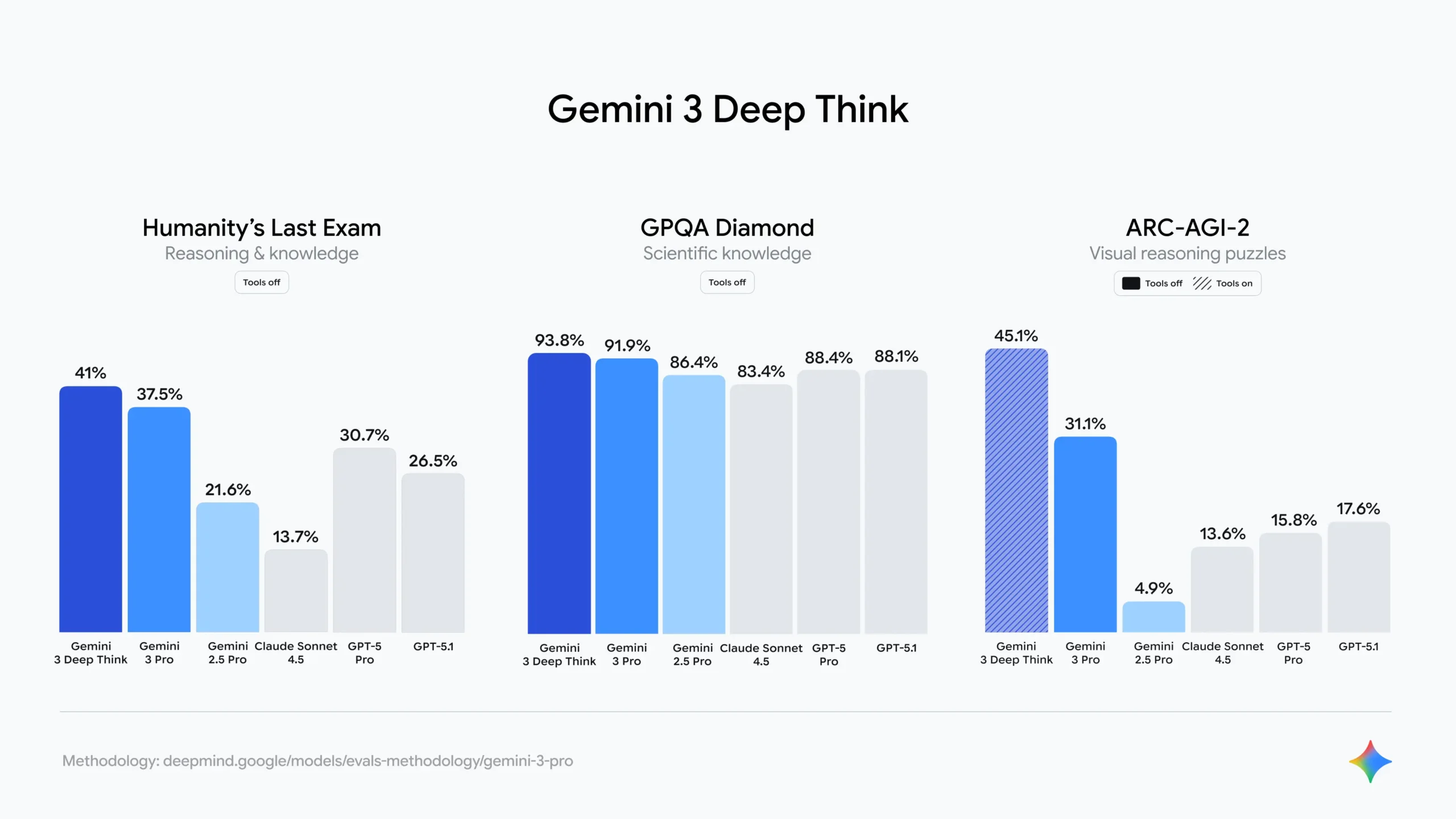
AGI Capability Metrics
What's fascinating about these metrics is how they reveal each model's philosophical approach to AGI. Gemini 3 Pro excels at abstract reasoning and multimodal integration, reflecting Google's focus on comprehensive understanding. Grok 4.1 dominates in contextual understanding, thanks to its massive context window. GPT-5.1 leads in autonomous problem solving and self-correction, showcasing OpenAI's emphasis on agentic capabilities.
The AGI Paradox
Interestingly, none of these models scores exceptionally high across all AGI metrics. This suggests we're approaching AGI not through a single breakthrough model, but through specialized systems that excel in different aspects of intelligence. The true AGI breakthrough may come from combining these approaches rather than improving one model to dominate all categories.
Real-World Scenarios
Benchmarks are great, but how do they perform when the clock is ticking? We ran three specific scenarios.
Scenario A: The "Startup Runway" Test
Task: Summarize 10,000 customer support tickets and categorize them by sentiment.
- Winner: Grok 4 Fast.
- Reason: It cost $1.50 to process. Gemini cost $12.00. GPT-5 cost roughly $10.00. The output quality was virtually identical for this simple task.
Scenario B: The "Legal Discovery" Test
Task: Find a contradiction between Clause 4.2 in a 2020 contract and a 2024 amendment, while citing the specific page.
- Winner: Gemini 3 Pro.
- Reason: Its long-context reasoning is more precise. It didn't just find the text; it explained *why* it was a contradiction legally. Grok found the text but missed the nuance.
Scenario C: The "Full Stack" Test
Task: Write a Python script to scrape a website, save data to SQL, and deploy it to a Docker container.
- Winner: GPT-5.1.
- Reason: It one-shot the entire script. Gemini required one prompt refinement. Grok struggled with the Docker configuration.
How to Get Better Output
If you aren't getting the results you want, the problem might not be the AI—it might be your prompt. Each model has a distinct "personality" you need to unlock.
Gemini: "The Upload Trick"
Don't copy-paste text into Gemini 3 Pro. Upload the file. When you upload a PDF or CSV, Gemini switches to a different processing mode that allows it to "see" the whole document at once. Pasting text fragments breaks this context. Always use the paperclip icon.
GPT-5: "Agentic Phrasing"
Stop asking GPT-5 to "write a plan." Instead, tell it to "Act as a Project Manager and create a step-by-step execution strategy." GPT-5 excels at role-playing. If you give it a specific job title (e.g., "Senior React Developer"), its output quality improves by roughly 20% because it accesses more specific training data.
Grok: "Context Stuffing"
Grok 4.1 loves data. If you have a vague question, paste everything relevant you have—emails, logs, previous drafts—into the chat first. Grok doesn't get "confused" by too much info like older models; it actually gets smarter the more noise you give it.
Personalization & Memory
In 2025, you shouldn't have to repeat yourself. Here is how the big three handle your personal data.
- Gemini "Gems": Google introduced "Gems"—custom versions of Gemini. You can build a "Coding Gem" that always replies in Python, or a "Writing Gem" that mimics your specific tone. These are static and highly reliable.
- ChatGPT Memory: OpenAI uses dynamic memory. If you tell it, "I have a peanut allergy" or "I prefer C++ over Rust," it remembers this across *all* future chats automatically. It feels more organic but can sometimes hallucinate details.
- Grok Toggles: xAI keeps it simple. You have toggles for "Fun Mode" (unfiltered) vs. "Regular Mode." It doesn't have deep memory features yet, but it respects your political and cultural preferences better than the others.
Full 2025 Feature Matrix
| Feature | Gemini 3 Pro | Grok 4.1 (Fast) | GPT-5.1 |
|---|---|---|---|
| Provider | Google DeepMind | xAI | OpenAI |
| Primary Strength | Complex Reasoning & Multimodality | Massive Context & Low Cost | Coding & Agentic Tasks |
| Context Window | 1 Million+ (Cached) | 2 Million | 400k (Standard) |
| HLE Benchmark | 45.8% (Leader) | Not Verified | ~42% |
| SWE-Bench Verified | 68% | 52% | 76% (Leader) |
| GPQA Diamond | 62.3% (Leader) | 48% | 58% |
| Pricing (Input) | $2.00 / 1M ($0.20 Cached) | $0.20 / 1M | Variable / Subscription |
| Best For | Enterprise & Legal | Data Analysis & Startups | Devs & Generalists |
Key Takeaways
After extensive testing across multiple benchmarks and real-world scenarios, several key insights emerge about the current state of AI in 2025:
Reasoning Revolution
Gemini 3 Pro's 45.8% score on Humanity's Last Exam represents a quantum leap in AI reasoning capabilities, far surpassing previous models.
Context is King
Grok 4.1's 2M token window isn't just a number—it fundamentally changes what's possible with AI analysis of large documents.
Autonomous Agents
GPT-5.1's self-correction capabilities mark the beginning of truly autonomous AI systems that can fix their own mistakes.
Economic Disruption
The 10x price difference between Grok and competitors is democratizing access to advanced AI capabilities for startups.
The most important takeaway is that we've moved beyond a one-size-fits-all approach to AI. Each model now serves a distinct purpose, and the "best" choice depends entirely on your specific use case. For enterprises dealing with complex reasoning tasks, Gemini 3 Pro is unmatched. For those processing massive amounts of text, Grok 4.1 is the only economically viable option. For developers and creators, GPT-5.1's agentic capabilities make it the clear winner.
What's particularly exciting is how these models complement each other. We're already seeing workflows that use all three: Grok for initial document processing, Gemini for deep analysis, and GPT-5 for implementation. This multi-model approach is likely to become the standard as we continue pushing toward AGI.



In the End
Best Overall
Gemini 3 Pro
Unmatched reasoning & multimodal tools.
Best Value
Grok 4.1
Massive 2M context at rock-bottom prices.
Best for Devs
GPT-5.1
Most reliable autonomous coding agent.



